
https://product.kyobobook.co.kr/detail/S000214934825
한 권으로 끝내는 실전 LLM 파인튜닝 | 강다솔 - 교보문고
한 권으로 끝내는 실전 LLM 파인튜닝 | 실무 현장에서 꼭 필요한 파인튜닝, PEFT, vLLM 서빙 기술을 직접 실습하면서 배워 보자!AI 기술의 최전선에서 배우는 LLM 파인튜닝의 모든 것! 이론적 토대부터
product.kyobobook.co.kr
"한 권으로 끝내는 실전 LLM 파인튜닝" 교재를 활용해 3주(주말 제외) 동안 진행 되는 온라인 스터디
VLLM(Versatile Large Language Model)이란?
VLLM이란 대규모 언어 모델의 배포를 더욱 효율적이고 확장 가능하게 만드는 추론 라이브러리이다.
Attention Key와 Value를 효과적으로 관리하는 Paged Attention(페이지드 어텐션)이라는 기술을 활용해 높은 처리량을 보여주는 LLM 서비스이다.
vLLM에 관련 내용은 해당 링크를 통해 자세히 알아볼 수 있다.
https://blog.vllm.ai/2023/06/20/vllm.html
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
GitHub | Documentation | Paper
blog.vllm.ai
기존 방식의 한계점 분석
LLM 추론(Transformer)의 특징
LLM의 핵심 요소인 Transformer는 입력(프롬프트)을 기반으로 하나씩 단어(token)을 생성한다. 모델은 입력과 지금까지 생성된 출력의 토큰 시퀀스에 기반하여 새로운 토큰을 생성하는 방식이다.

순차적인 생성 과정에서 모델은 각 단계에서 하나의 토큰을 입력으로 받고, 모든 이전 토큰의 키(key) 및 값(value) 벡터를 사용하여 다음 토큰의 확률을 계산 (Autoregressive, 자기회귀)
이 때, 이전 토큰에서 생성된 키 및 값 벡터는 KV Cache에 저장되며, 각 반복 단계에서 새로운 키 및 값 벡터만이 계산된다. 해당하는 순차적인 생성과정은 GPU의 계산 능력을 활용하지 못한다. == Serving 처리량을 제한.
KV Cache 방식은 계산 효율이 높지만, 입력 시퀀스가 길어질수록 저장해야 할 정보량이 급격히 증가한다.
-> 메모리상에 연속적으로 저장되어야 하는데, 이 과정에서 메모리 사용량이 크게 늘어나는 문제점 발견.
비효율적인 KV Cache 메모리 관리

대부분의 딥러닝 프레임워크에서 텐서를 연속적인 메모리에 저장해야 하기에, LLM 시스템들은 앞서 설명한 KV Cache를 연속적인 메모리 공간에 저장하는 방식을 사용한다.
LLM의 특성상 출력 길이가 예측이 불가능하고, 얼마나 긴 텍스트를 생성할지 모르기 때문에 공간을 미리 확보하고 해당 과정에서 3가지 주요 메모리 낭비 문제가 발생한다.
- 내부 메모리 단편화(Internal Memory Fragmentation) : 기존 LLM은 요청의 최대 길이에 해당하는 메모리 공간을 미리 확보하고, 실제 요청 길이가 훨씬 짧은 경우 미리 확보한 공간의 일부만 사용되어 나머지 공간이 낭비되는 문제
- 외부 메모리 단편화(External Memory Fragmentation) : 여러 요청을 동시에 처리할 때 각 요청의 길이가 서로 다르면, 메모리에 빈 공간이 생기는 문제
- 메모리 예약(Reserved Memory) : 요청마다 최대 길이에 해당하는 메모리를 예약하게 되면, 현재 단계에서는 사용되지 않지만 미래에 사용될 것으로 예상되어 미리 공간을 확보해 두는 문제
기존 방식의 한계점
기존의 LLM 서빙 시스템이 KV Cache Memory를 효율적으로 관리하지 못함
기존 방식의 제안점
운영체제의 가상 메모리 및 페이징 기술에 영감을 받아 PagedAttention으로 KV Cache 메모리의 낭비를 줄이고, 요청 간 및 요청 내에 유연한 공유를 가능하게하여 LLM 서빙 시스템의 처리량을 향상
Paged Attention
주요 특징
- Logical KV Cache blocks는 모델이 처리하는 데이터의 논리적 구조를 나타냄
- Block table은 이 논리적 구조와 실제 물리적 메모리 위치를 연결하는 중개자 역할
- Physical KV Cache blocks는 실제 데이터가 저장되는 물리적 메모리 공간






Prompt : "Alan Turing is a computer scientist"로 처리 과정을 알아보자
- Prompt가 처리되어 Logical KV Cache blocks에 저장, Block0에 'Alan Turing is a'가, Block1에 'computer scientist'가 저장된다. Physical KV Cache blocks에서 Block7과 Block1이 이 데이터를 저장하는데 사용되고, Block table은 이 매핑 정보를 기록
- 모델이 'and'를 생성하면서 이 토큰을 Logical KV cache의 Block1과 Physical KV Cache의 Block1에 각각 추가된다. Filed slots가 2에서 3으로 업데이트
- 모델이 'mathematician'이라는 두번째 토큰을 생성. 이 토큰은 Logical KV Cache의 Block1과 Physical KV Cache의 Block1에 추가되고, Block table의 Filied slots는 4로 업데이트
- 모델이 'renowned'라는 세 번째 토큰을 생성. Logical KV Cache의 Block1이 가득 찼으므로, 새로운 Block2에 할당. Physical KV Cache에서는 새로운 Block3이 할당되어 이 토큰을 저장. Block table에 새로운 행이 추가되어 이 정보를 기록
- 모델이 'for'라는 네 번째 토큰을 생성. Logical KV Cache의 Block2와 Physical KV Cache의 Block3에 각각 추가.Block table에 Filied slots는 2로 업데이트
이와 같이 PagedAttention(페이지드 어텐션)방법을 적용해 LLM의 추론에 사용하였을 때,
논문 참고. https://arxiv.org/abs/2309.06180?ref=pangyoalto.com
Efficient Memory Management for Large Language Model Serving with PagedAttention
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. Whe
arxiv.org
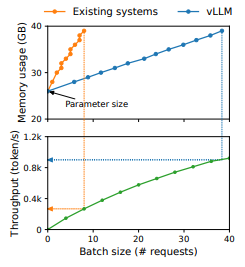
동일한 양의 메모리를 훨씬 더 많은 양의 데이터를 처리하는 것을 확인되었고, 기존의 KV Cache 메모리 관리 방법보다 훨씬 더 효율적임을 알 수 있다.
RunPod Serverless(vLLM Docker)로 LLM 배포
RundPod의 Serverless(vLLM Docker)를 활용하면 학습된 AI 모델을 안정적이게 활용이 가능하다.
Serverless는 서버에 요청이 들어왔을 때만 GPU가 실행되고, GPU가 작동한 초당 사용량으로 비용을 지불하여, GPU 서버를 통째로 빌리거나 시간당 빌렸을 때보다 유연하게 사용이 가능하다.
또한,
- 24시간 내내 가동 상태 유지 가능
- 필요에 따라 컴퓨팅 리소스를 조절 가능
- 특히 다수의 사용자가 동시에 접속하는 서비스나 신속한 응답이 중요한 챗봇 서비스나 다량의 사용자 요청을 동시에 처리해야 하는 이미지 분석 서비스에 활용이 가능
- Runpod Serverless vLLM Endpoint를 이용하여 HuggingFace 모델을 클라우드에서 실행이 가능
https://blog.runpod.io/how-to-run-vllm-with-runpod-serverless-2/
How to run vLLM with RunPod Serverless
In this blog you’ll learn: 1. When to choose between closed source LLMs like ChatGPT and open source LLMs like Llama-7b 2. How to deploy an open source LLM with vLLM If you're not familiar, vLLM is a powerful LLM inference engine that boosts performance
blog.runpod.io
참고
https://docs.vllm.ai/en/latest/index.html#
https://blog.vllm.ai/2023/06/20/vllm.html
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
GitHub | Documentation | Paper
blog.vllm.ai
'DL > LLM&RAG' 카테고리의 다른 글
| 한 권으로 LLM 온라인 스터디 1기 Day_14 - QLoRA 실습 (1) | 2025.01.21 |
|---|---|
| 한 권으로 LLM 온라인 스터디 1기 Day_13 - QLoRA 이론 (0) | 2025.01.21 |
| 한 권으로 LLM 온라인 스터디 1기 Day_12 - 효율적인 파라미터 튜닝(PEFT) - LoRA 개념 및 실습 2장 (1) | 2025.01.21 |
| 한 권으로 LLM 온라인 스터디 1기 Day_11 - 효율적인 파라미터 튜닝(PEFT) - LoRA 개념 및 실습 1장 (0) | 2025.01.20 |
| 한 권으로 LLM 온라인 스터디 1기 Day_10 - 다중 GPU를 활용한 Llama3.1-8B-instruct 파인튜닝 (2) | 2025.01.20 |