Scaling Laws for Neural Language Models
https://arxiv.org/abs/2001.08361
Scaling Laws for Neural Language Models
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitu
arxiv.org
Scaling Laws for Neural Language Models은 GPT-3에서도 언급되었으며, LLM의 중요한 기반이 되는 논문이다.
OpenAI에서 발표한 논문으로 언어 모델에서의 데이터와 모델 사이즈를 늘리는 것에 대한 체계적인 연구를 다룬 LLM의 이론적 실험적인 증거를 체계적으로 연구한 논문이다.
간략하게 그림과 설명으로 정리해볼 계획이다.
Abstract
cross-entropy를 사용하는 scaling law for Language Models에 대한 empirical(경험적) 실증적인 연구이다.
모델의 크기, 데이터셋 크기, 학습에서 사용되는 계산량을 간단한 Power law와 log scale로 표기 할 수 있다.
Overfitting과 Model / Dataset 크기, 학습 속도와 모델 크기를 간단한 방정식으로 표현할 수 있다.
Summary
Performance depends strongly on scale, weakly on model shape
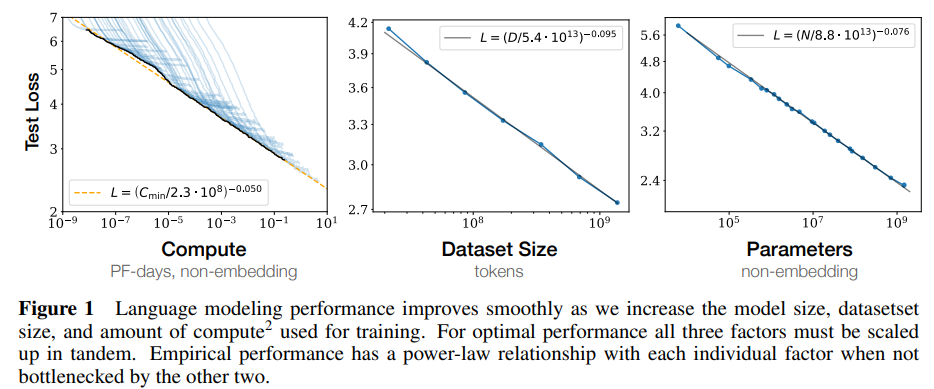
- 모델 성능은 크게 3가지에 의해 영향을 받는다.
- Model Size (The Number of model parameters) : 모델 파라미터 수, N 지칭
- Dataset Size : 데이터셋 크기, D 지칭
- The Amount of Compute used for training : 학습에 사용되는 계산량, C 지칭
- 반면, 모델 아키텍처의 세부 구조(Depth, Width 등)은 상대적으로 작은 영향을 미친다
Smooth Power Laws
- 성능은 N, D, C 각각에 대하여 power-law 관계를 따른다.
- 단, 다른 두 요인(N, D, C)에 의해서 병목(bottleneck)현상이 되지 않는다는 조건 하에서만 성립한다.
- 해당 관계는 6 order of magnitude(백만 배) 이상의 범위에서도 적용된다.
Universality of Overfitting
- N과 D를 함께 늘리면 성능은 향상하지만, 하나를 고정한 상태로 다른 하나를 늘린다면 수확 체감(diminishing returns)이 발생한다.
- 오버피팅을 방지하는 최적 관계 : N0.74/D (D∝N0.74)
- 즉, 모델 크기가 8배 증가하면 데이터셋을 약 5배 증가시켜야 동일한 일반화 성능을 유지할 수 있다.

테스트 손실 L(N,D)은 모델 크기 N과 데이터셋 크기 에 따라 예측 가능한 패턴을 보인다.
- 데이터셋이 충분히 큰 경우 (D가 클 때), 성능은 N에 대하여 직선적인 거듭제곱 법칙(Power-law)를 따른다.
- 하지만, D가 고정된 상태에서는, N이 커질수록 성능 향상이 멈추고 모델이 과적합(Overfitting)이 되기 시작한다.
- (해당 관계는 반대로도 성립하며, 이에 대해서는 오른쪽 그림을 참고하면 된다.)
데이터가 충분히 클 때는 손실이 에 대해 거듭제곱 법칙(Power-law)을 따르며 감소하지만, 데이터가 작을 경우 모델이 커질수록 성능 향상이 멈추고 과적합이 발생한다.
Universality of training
- 학습 진행에 따라 loss가 감소하는 속도 또한 power-law 형태의 학습 곡선을 따른다.
- 초기 학습 곡선만으로도 향후 수렴 시점과 최종 성능을 예측할 수 있다.

계산량이나 학습 스텝을 일정하게 유지할 때, 성능은 L(N,S) 관계식을 따른다.
계산 자원량이 주어지면 그에 맞는 최적의 모델 크기가 존재하며, 너무 작은 스텝에서는 학습 초기에 거듭제곱 법칙이 잘 적용되지 않아 예측 정확도가 떨어진다.
Transfer improves with test performance
- 모델을 학습 데이터 분포와 다른 텍스트에서 평가했을 때, loss는 validation loss와 거의 일정한 offset 관계(constant offset)를 보인다.
- 다른 분포의 데이터로 전이학습 penalty를 주지만 예측 가능한 수준이며, 그 외의 경우에서는 학습 데이터에 대해서 성능 향상이 발생한다.

1.5B 파라미터 규모의 모델들을 여러 데이터셋에서 평가한 결과, 모델 깊이는 일반화 성능에 유의미한 영향을 주지 않았다.
일반화 성능은 주로 훈련 데이터에서의 성능에 의해 결정되며, 12개의 레이어로 구성된 InternetBooks 데이터셋에서는 과적합이 되었으며, 그에 따른 조기 종료(early-stopped)된 결과를 제시한다.
모델의 깊이(Depth)는 일반화 성능(Generalization)에 거의 영향을 미치지 않았다.
Sample Efficiency
- 큰 모델일수록 작은 모델보다 샘플 효율적(sample-efficient)이다.
→ 같은 수준의 loss를 달성하기 위해 더 적은 데이터와 더 적은 step이 필요하다.
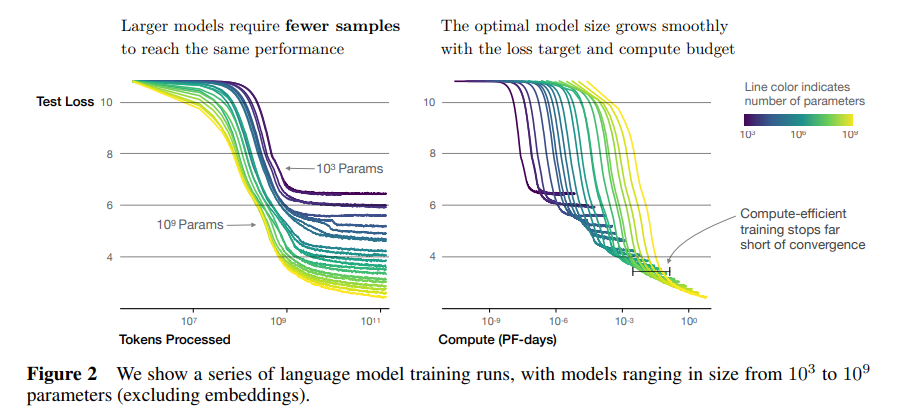

Convergence is inefficient
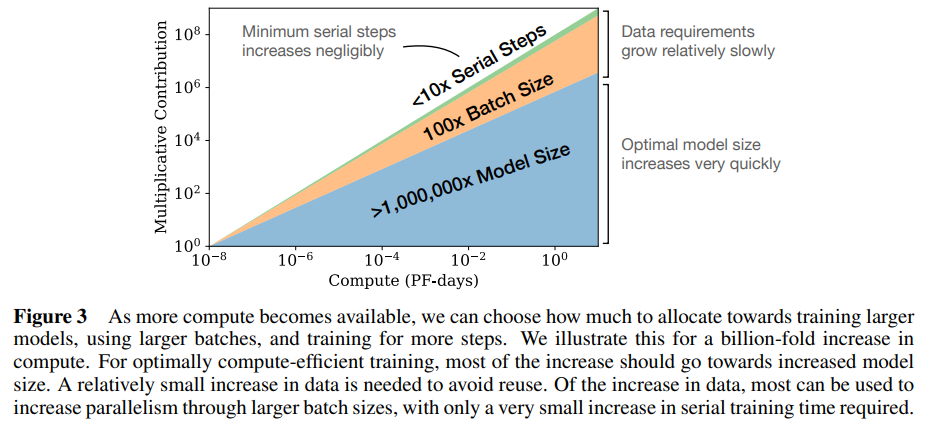
- 연산량 C가 고정된 상태에서 N과 D를 제한없이 조정하면, very large models는 학습을 수행할 때 수렴하지 않음에도 early stopping을 적용함으로써 최적에 근접할 수 있다.
- compute-efficient training은 생각보다 훨씬 적은 데이터로도 계산 효율적인 학습이 가능하다는 뜻이다.
Optimal batch size
- 최적 배치 크기는 loss에 대한 power-law 관계로 표현되며, gradient noise scale로부터 추정 가능하다.
- 저자들이 학습한 가장 큰 모델의 경우, 약 2M(약 200만) tokens 배치에서 수렴 가능함을 보였다.

임계 배치 크기 (Critical Batch size, B_crit)는 성능이 향상될수록 손실(loss)과 Power law 관계를 따르며, 모델 크기에는 직접적으로 의존하지 않는다.
실험 결과. 손실이 13% 감소할때마다 임계 배치 크기가 약 2배씩 증가함을 확인했다.
[MKAT18]에서 제시된 것처럼 gradient noise scale로도 대략적으로 예측할 수 있다.
Reflections
Scaling Laws for Neural Language Models 논문을 읽으면서, 최근 대규모 언어 모델(LLM)에서 파라미터 수가 지속적으로 증가하는 이론적·경험적 근거를 명확히 이해할 수 있었다.
모델 크기, 데이터셋 크기, 계산량 간의 관계가 단순한 경험적 결과가 아니라 일정한 Scaling laws를 따른다는 점을 자세히 확인하였고, 효율적으로 자원을 활용하여 성능을 극대화 하는 방향을 제시해주는 것 같았다.
이후 등장한 양자화(Quantization), 경량화 모델(sLLM), Mixture of Experts (MoE) 등의 연구 역시 이러한 스케일링 법칙의 한계를 극복하고, 제한된 리소스 안에서 최대의 성능을 얻기 위한 시도로 이해할 수 있었다.